Token nima va nega AI narxi shunga bog‘liq
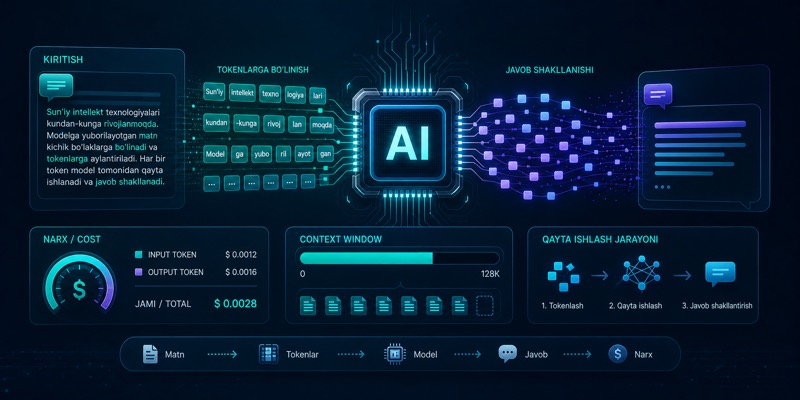
AI servislaridan foydalanganda bir joyda albatta token degan tushunchaga duch kelasiz. Ayniqsa API bilan ishlasangiz, narx ham, limit ham, context window ham shu token atrofida aylanadi. Lekin boshlovchi uchun bitta savol tabiiy: token o‘zi nima?
Ko‘p odam tokenni so‘z deb o‘ylaydi. Bu taxmin qisman to‘g‘ri, lekin aniq emas. Chunki model matnni biz ko‘radigan ko‘rinishda emas, maydaroq bo‘laklarga ajratib ishlaydi. Ana shu bo‘laklar token hisoblanadi.
Token nima?
Token - model matnni qayta ishlash uchun ishlatadigan birlik. U har doim bitta to‘liq so‘z bo‘lavermaydi. Ba’zan bitta so‘z bir nechta tokenga bo‘linadi, ba’zan esa tinish belgilari yoki kichik bo‘laklar ham token bo‘ladi.
Masalan, qisqa va oddiy inglizcha so‘z bitta token bo‘lishi mumkin. Uzunroq, murakkabroq yoki qo‘shimchali so‘z esa ikki yoki undan ko‘p token bo‘lib ketishi mumkin. O‘zbek va rus kabi tillarda bu farq yanada seziladi.
Nega narx token bo‘yicha olinadi?
Model uchun xarajat matnning “qiziqliligi”ga emas, uni qayta ishlash hajmiga bog‘liq. Prompt qancha uzun bo‘lsa, model shuncha ko‘p tokenni o‘qiydi. Javob qancha uzun bo‘lsa, model shuncha ko‘p token ishlab chiqaradi. Shu sababli AI provayderlar odatda hisob-kitobni token orqali qiladi.
Oddiyroq aytganda: siz modelga ko‘proq matn berasiz, u ko‘proq hisoblash qiladi. U ko‘proq matn qaytaradi, yana ko‘proq hisoblash qiladi. Narx shundan chiqadi.
Input token va output token
Ko‘p servislar input va output tokenni alohida hisoblaydi.
- Input token - modelga yuborilgan matn: system prompt, user prompt, context, hujjat parchalari.
- Output token - model qaytargan javob.
Ba’zi modellarda output token narxi inputdan qimmatroq bo‘ladi. Shu sababli juda uzun javob so‘rash ba’zan sezilarli xarajat qiladi.
Context window bilan qanday bog‘liq?
Context window - model bir urinishda ko‘ra oladigan maksimal token hajmi. Bu yerga system prompt, oldingi xabarlar, hujjatlar va joriy savolning hammasi kiradi. Javob uchun ham joy kerak bo‘ladi.
Agar siz juda uzun prompt, katta hujjat va uzun chat tarixini birga yuborsangiz, ikki muammo chiqadi: narx oshadi va kerakli ma’lumot context oynasida siqilib qolishi mumkin. Shuning uchun contextni tanlab berish muhim.
Nimalar tokenni tez ko‘paytiradi?
- juda uzun system prompt,
- keraksiz uzun chat history,
- to‘liq hujjatni yuborish, lekin undan kichik parcha kifoya bo‘ladigan holatlar,
- juda uzun va takroriy javob so‘rash,
- bir xil contextni qayta-qayta yuborish. Buni caching kamaytirishi mumkin.
Ko‘pincha mahsulotdagi “AI qimmat chiqyapti” muammosi modeldan emas, kontekst va promptning ortiqcha uzunligidan keladi. Xuddi shu ortiqcha uzunlik latencyni ham oshiradi.
Narxni kamaytirishning amaliy usullari
- Promptni qisqa, lekin aniq yozing.
- Keraksiz chat tarixini tozalang.
- To‘liq hujjat o‘rniga relevant parcha yuboring.
- RAG ishlatsangiz, faqat kerakli chunk’larni qaytaring.
- Javob uzunligini cheklang: masalan, 5 punkt, 1 paragraf, 100 so‘z.
- Arzonroq model yetadigan vazifaga qimmat model ishlatmang.
Xulosa
Token - AI iqtisodiyotining asosiy birligi. Model matnni tokenlar orqali ko‘radi, narx ham shunga qarab olinadi, limit ham shunga qarab belgilanadi. Shu sababli prompt, context va javob uzunligini boshqarish - faqat texnik masala emas, xarajat masalasi hamdir.
Qisqasi, yaxshi AI ishlatish degani faqat yaxshi savol berish emas. Ba’zan u kamroq token bilan ko‘proq foyda olishni ham anglatadi.