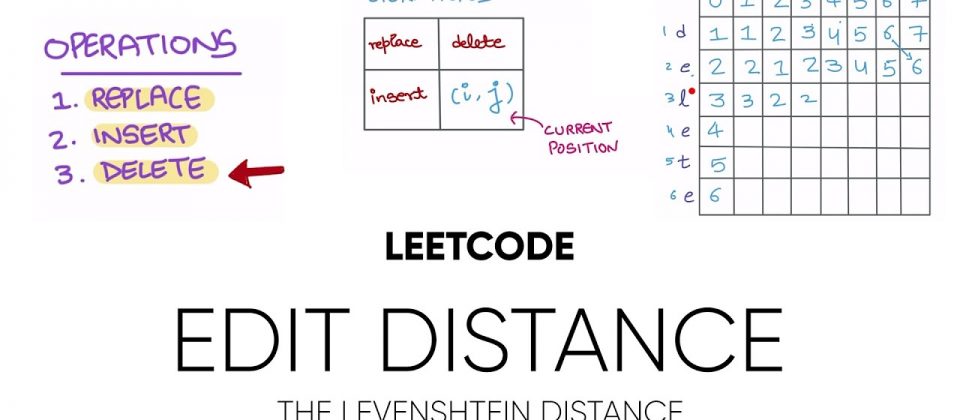
Leetcode 9. Palindrome Number
x son berilgan, funksiya agar x palindrom bo’lsa true, aks holda false qaytarishi kerak. Palindrom son deb ohiridan boshiga qarab o’qilganda ham bir xil chiqadigan sonlarga aytiladi. Masalan, 121 – palindrom, 123 – palindrom emas. Shuningdek, -121 ham palindrom emas, chunki teskari o’qilganda 121- bo’lib qoladi.