Matn ichida so’z/ibora qidiruv (substring search) algoritmlari bilan tanishib chiqishni boshlaymiz. Qo’yiladigan masala juda oddiy. N uzunlikdagi matn ichidan M uzunlikdagi iborani (pattern) topish kerak bo’lsin. Bunda matn juda katta hajmda, pattern esa juda kichik – bir-ikki so’zdan iborat.
Matn ichida qidiruv masalalari amaliyotda hujjatlar ichidan kerakli so’zni qidirishda, email kontent ichidan shubhali so’zni topib spam qilib belgilashda, web-sahifadan ma’lumotni ko’chirishda (web-scraping), internet traffikni nazorat qilishda, va h.k. ishlatiladi. Katta hajmdagi ma’lumotlar bilan ishlashda esa qidiruvning tez amalga oshishi muhim rol o’ynaydi.
Stringda kerakli so’zni qidirish uchun dasturlash tillarida tayyor funksiyalar allaqachon mavjud. Masalan, Javascriptda str.indexOf(pattern) funksiyasi qidirilayotgan so’zni (pattern) topib, uning birinchi belgisi joylashgan indeksni qaytaradi.
Biz xorijiy big-tech kompaniyalarga ishga kirish intervyusiga tayyorlanish uchun, matn ichida qidiruv algoritmlarini o’rganamiz.
Brute-force yondashuvi
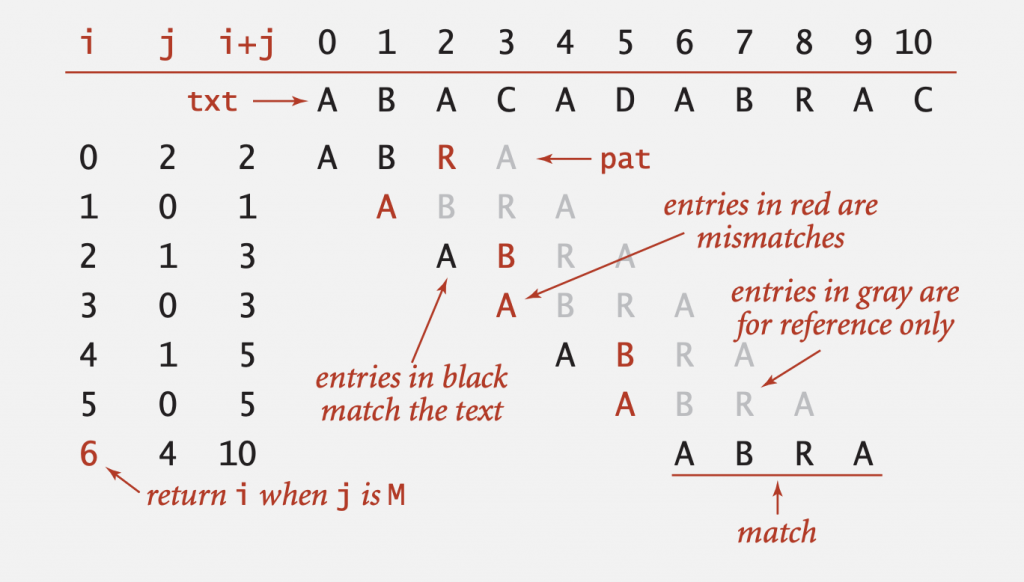
Odatiy usul albatta ikki siklda ishlaydigan brute-force algoritmi bo’ladi. Demak, bizda quyidagi matn bor bo’lsin: ABACADABRAC. Biz uning ichidan ABRA so’zini qidiramiz.
Birinchi sikl i = [0..N] gacha yoki ikkinchi siklda j = M bo’lguncha ishlaydi. Bunda N – matnning uzunligi, undagi belgilar soni.
Ikkinchi sikl j = [i…M] gacha yoki str[i + j] != pattern[j] bo’lguncha ishlaydi. Bunda M – pattern uzunligi.
Kod
Kodning ishlash vaqti – O(N * M). N * M, ya’ni worst case holati matnda qaytariluvchi belgilar ko’pligida bo’ladi. Masalan, matn AAAAAAAAAB va pattern AAAAB bo’lsa, patternni topguncha har safar ikkinchi (ichki) sikl j < M – 1 gacha ishlaydi.

Katta matnlar bilan ishlash uchun brute-force yondashuvi ma’qul yo’l emas, u ko’p vaqt talab qiladi. Nazariy jihatdan pattern’ni linear vaqtda – O(N) da topish ideal variant bo’lardi.
Keyingi maqolalarda matn ichida qidiruvning samaraliroq algoritmlarini ko’rib o’tamiz.