Regular Expressions va Nondeterministic Finite Automaton

Regular Expression algoritmiga o’tishdan avval NFA – Nondeterministic Finite Automaton abstrakt hisoblash mashinasi haqida tanishib chiqish kerak bo’ladi.
Dasturchi, frilanser, gik va introvert
Regular Expression algoritmiga o’tishdan avval NFA – Nondeterministic Finite Automaton abstrakt hisoblash mashinasi haqida tanishib chiqish kerak bo’ladi.

Regular expression (yana regex, regexp) – qidirish patternini belgilab beruvchi belgilar ketma-ketligi. Odatda regex’lar matn ichida qidiruv algoritmlarida so’zlarni topish (find), topish va almashtirish (find & replace), hamda kiritilgan ma’lumotni tekshirish uchun ishlatiladi.

Matn ichida qidiruv uchun yana bir diqqatga molik algoritmlardan biri – Rabin-Karp algoritmi hashing usuliga asoslanadi. Uning ishlash tartibini batafsil tushuntirishga harakat qilaman.

Avvalgi mavzuda o’tganimiz – Knuth-Morris-Pratt algoritmi yordamida biz matn ichida qidiruvni O(N + M) vaqt ichida bajara olamiz. Navbatdagi algoritm – Boyer-Moore algoritmi bizga O(N) ni kafolatlay olmasada, amaliyotda KMPdan samaraliroq ishlaydi. O’rganishga ham osonroq 😉

Matn ichida qidiruv uchun brute-force yondashuvining kamchiligi – pattern’dagi belgilardan biri qidiruvda mos kelmay qolganda, qidiruvni boshqatdan boshlashi kerak. Shuning uchun worst case O(N*M) bo’lib ketadi.

Awakening Bangkok – yorug’lik dekoratsiyalarini o’z ichiga olgan festival bo’lib, har yili o’tkazib kelinar ekan. Men faqat bu yilgi festivalni tasodifan (har doimgidek) bilib qoldim va o’tgan shanbada dekoratsiyalarni aylanib chiqdim.
Matn ichida so’z/ibora qidiruv (substring search) algoritmlari bilan tanishib chiqishni boshlaymiz. Qo’yiladigan masala juda oddiy. N uzunlikdagi matn ichidan M uzunlikdagi iborani (pattern) topish kerak bo’lsin. Bunda matn juda katta hajmda, pattern esa juda kichik – bir-ikki so’zdan iborat.
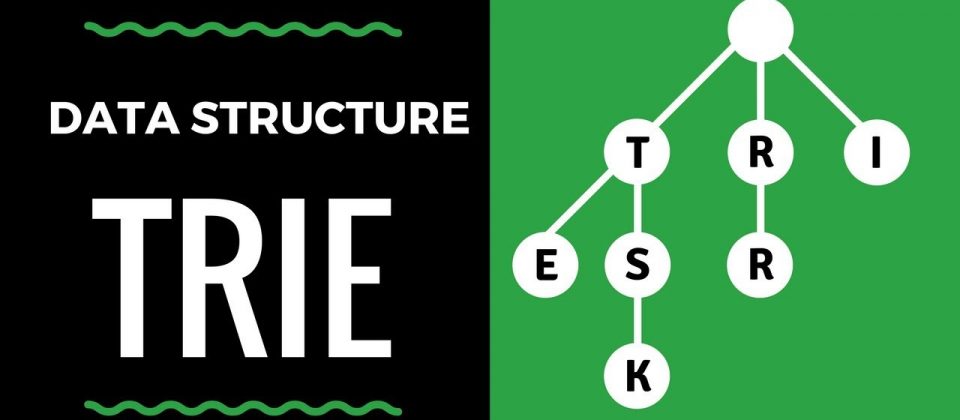
Ushbu maqolada biz ba’zi string amallarini R-way trie ma’lumot tuzilmasida ko’rib o’tamiz.
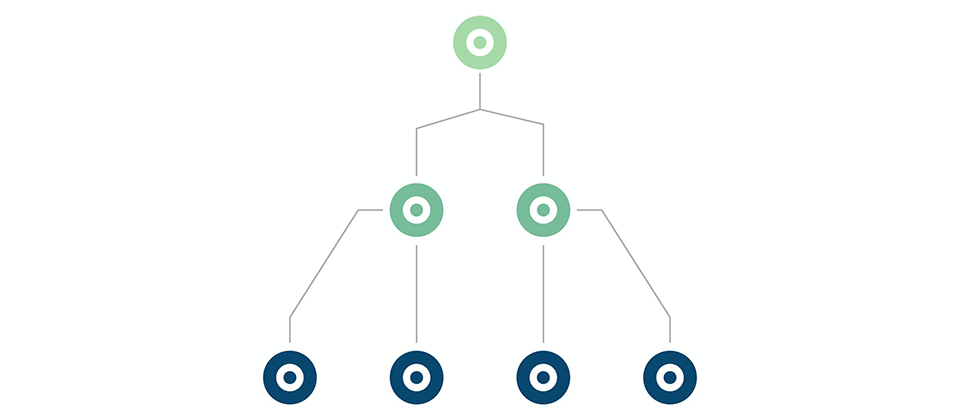
Ternary search tries (TST, uchlamchi qidiruv trie) R-way tries’dagi kamchilikka yechim o’laroq tavsiya etiladi. TSTda belgilar indeks ko’rinishida emas, node ichida saqlanadi (R-way tries’da belgilar indeks nomer sifatida saqlanardi). Shuningdek har bir node uch child’ga ega: kichikroq (chap), teng (o’rtada), kattaroq (o’ngda).
Ushbu mavzu string key’lar qidiruvi uchun mo’ljallangan ma’lumotlar tuzilmasi – tries (trays) haqida bo’ladi. Shu vaqtgacha ko’rib o’tgan ma’lumotlar tuzilmalaridan qidiruv uchun eng yaxshisi red-black tree – key’ni qidirish / qo’shish / o’chirish uchun O(log N) vaqtni kafolatlardi.